RedactionBench
- A10 Networks, Inc.
* Corresponding author: sbrynjolfson@a10networks.com
Abstract
LLMs are increasingly being applied to sensitive domains that require redacting personally-identifiable information (PII) before processing. While redacting PII has become a de facto data-cleaning prerequisite, existing benchmarks conflate the mechanics of extraction with the semantics of privacy. A phone number in a public directory is not equivalent to one in a medical record. Whether a given piece of information constitutes a violation depends heavily on who holds it, why, and in what context—fundamentally differentiating the redaction task from simple entity recognition. Grounded in this principle of contextual integrity, we introduce RedactionBench, a manually annotated benchmark comprising 200 diverse documents across 11 domains, with a majority seeded from real-world sources. RedactionBench also introduces a novel character-level redaction metric called R-Score that treats semantically similar redactions equally and nullifies the impact of shallow formatting choices (e.g., redacting a phone_number as: "(***) ***-****" vs. "**************"). Extensive evaluations across Named-Entity Recognition (NER) models, entity-extraction Small Language Models (SLM), and frontier LLMs equipped with agentic tools (Claude Opus, OpenAI GPT) demonstrate that contextual redaction remains an unsolved problem. Results from our human evaluation (85 participants) on RedactionBench reveal a stark dichotomy in privacy perception: annotators show consensus with our target labels for mandatory redactions (89.4%) and safe text preservations (94.1%), but fail to agree with contextual redactions (47.7%). This variance demonstrates the subjective nature of contextual privacy and motivates our evaluation metric R-Score, which decouples contextual ambiguity from strict redaction precision. We compare 35 models using RedactionBench across model families and report their performance for PII redaction. Finally, we release RedactionBench publicly to establish a baseline for future privacy-preserving redaction systems. We hope this benchmark inspires a shift towards efficient model design and standardized evaluations for text redaction.
Interactive R-Score
Select text to redact it. Click a redaction to remove it.
Text selection in this interactive does not work on mobile. Use Randomize redactions to explore different combinations instead.
Evaluations
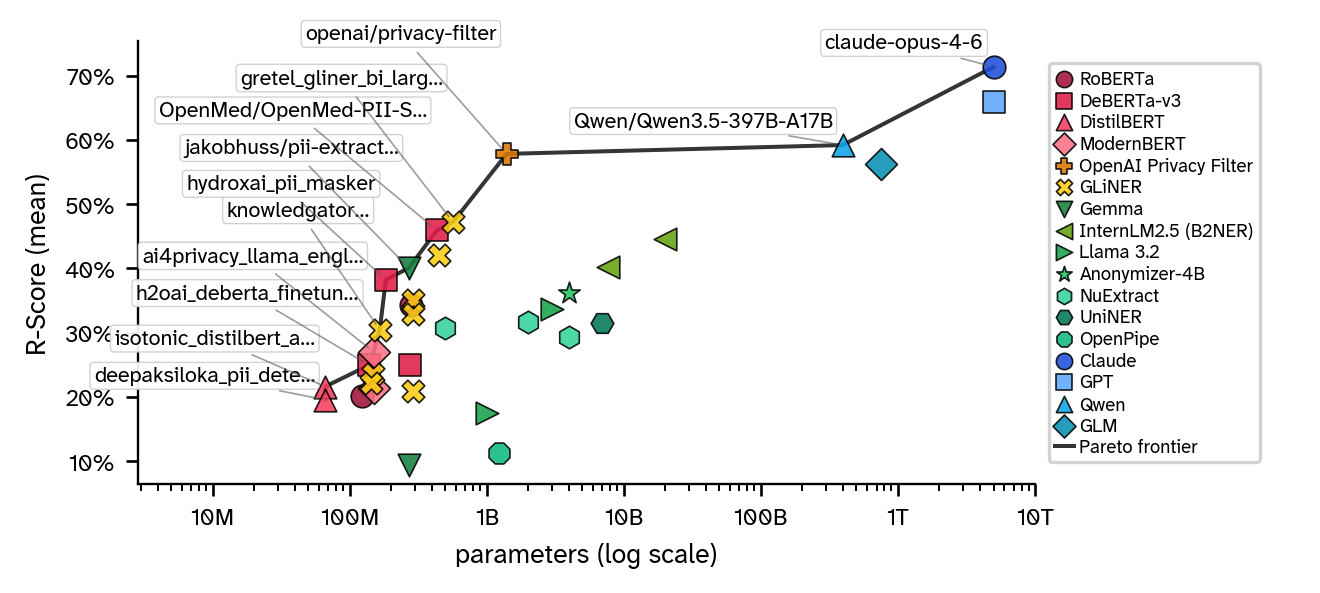
Overall Model Leaderboard
† h2oai/deberta_finetuned_pii and lakshyakh93/deberta_finetuned_pii are mirrored uploads of the same checkpoint and produce identical scores.
Data Samples
Citation
@misc{brynjolfsson2026redactionbench,
title = {RedactionBench},
author = {Brynjólfsson, Sean and Jayakrishnan, Shashvat and Sali, Esha and Purwar, Diptanshu and Aggarwal, Madhav},
year = {2026},
eprint = {2606.18782},
archivePrefix = {arXiv},
primaryClass = {cs.CL},
doi = {10.48550/arXiv.2606.18782},
url = {https://arxiv.org/abs/2606.18782}
}