" . . . Practice any art, music, singing, dancing, acting, drawing, painting, sculpting, poetry, fiction, essays, reportage, no matter how well or badly, not to get money and fame, but to experience becoming, to find out what's inside you, to make your soul grow. " — Kurt Vonnegut
Sean Brynjólfsson
Bismarck, ND → Ithaca, NY → San José, CA

Hi! I’m Sean, I recently joined A10 Networks to work on scaleable safety mechanisms for multimodal language models (MLLMs)! 🎉
I’m also a pianist/composer, hockey player, painter, graphic designer, fly-fisherman, Old Norse/Classical Latin poetry enthusiast, and soon-to-be figure skater.
I graduated from Cornell University (‘25) with a B.S. in Computer Science, where I focused on graphics, computer vision, robotics, and agricultural technology. I was a member of Prof. Donald Greenberg’s lab and also his head TA for his course Visual Imaging in the Electronic Age. I also TA’d for Deep Learning under Profs. Killian Weinberger and Jennifer Sun.
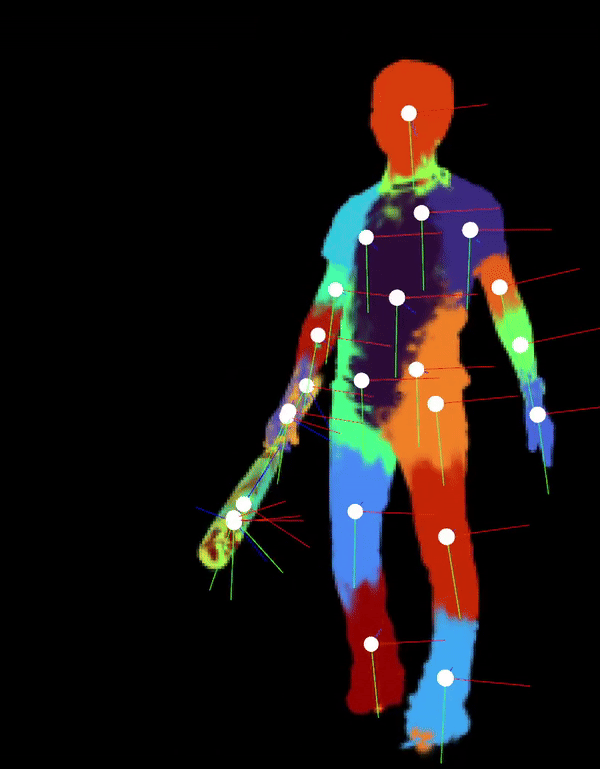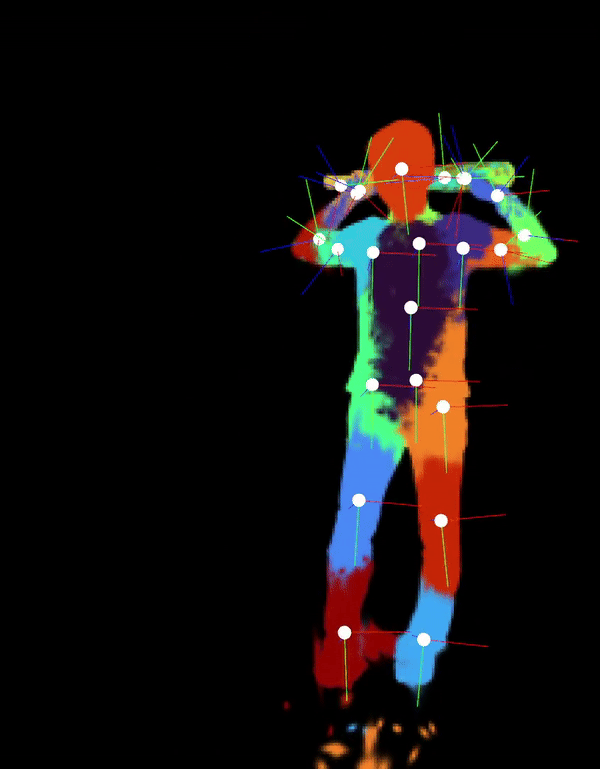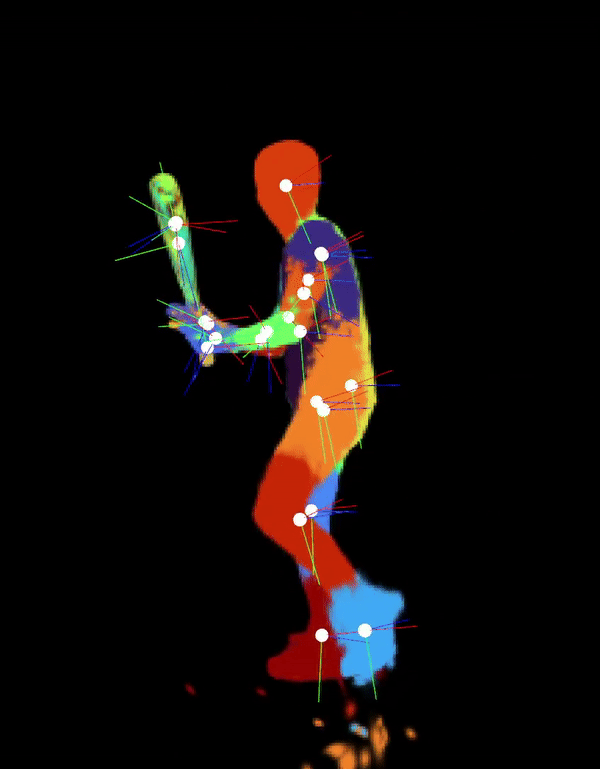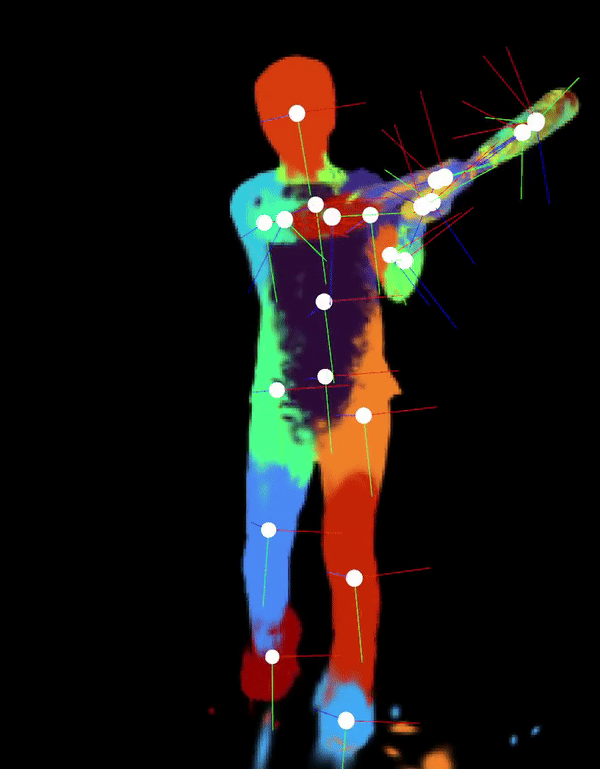
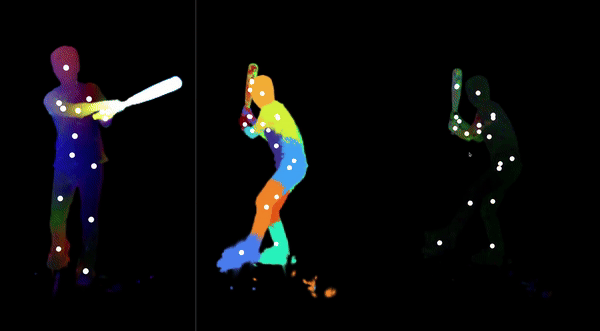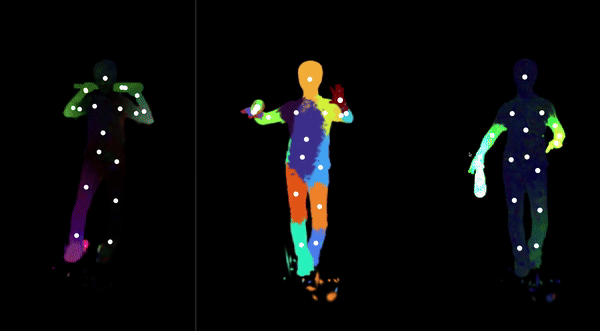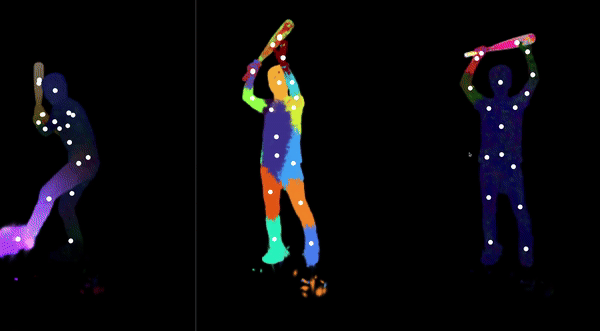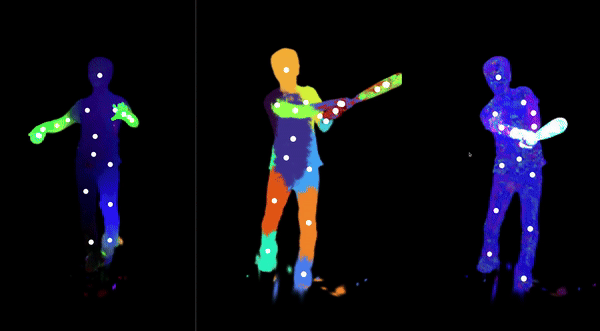
Automatically-Rigged Gaussian Characters
Sean Brynjólfsson*, Justin Tien-Smith*, Evan Zhang*
Recently, techniques for solving gaussian splats of dynamic scenes (Dynamic3DGaussians, 2024) have found success in using local rigidity constraints to enforce spatial and temporal consistency.
We use this detailed representation and decompose it into the rigid parts and joints which describe their movement. This procedure makes no assumptions about the anatomy of the dynamic entities within the scene and therefore should work equally well for all people, animals, machines—anything that moves about a discrete set of joints. We’re currently implementing the joint solver after getting promising results for our clustering algorithm to find the bones.
Our final deliverable will be an animation-ready gaussian rig and a portable format for them. Clustering also massively downsizes the storage requirements because local rigidity means gaussians are predictive of their neighbors—no need to track all of them. We are also developing more visualizations to help understand the limitations of the representation present. In doing so, we have spotted some new failure modes of the original method, like how some regions gradually creep into neighboring regions over time.
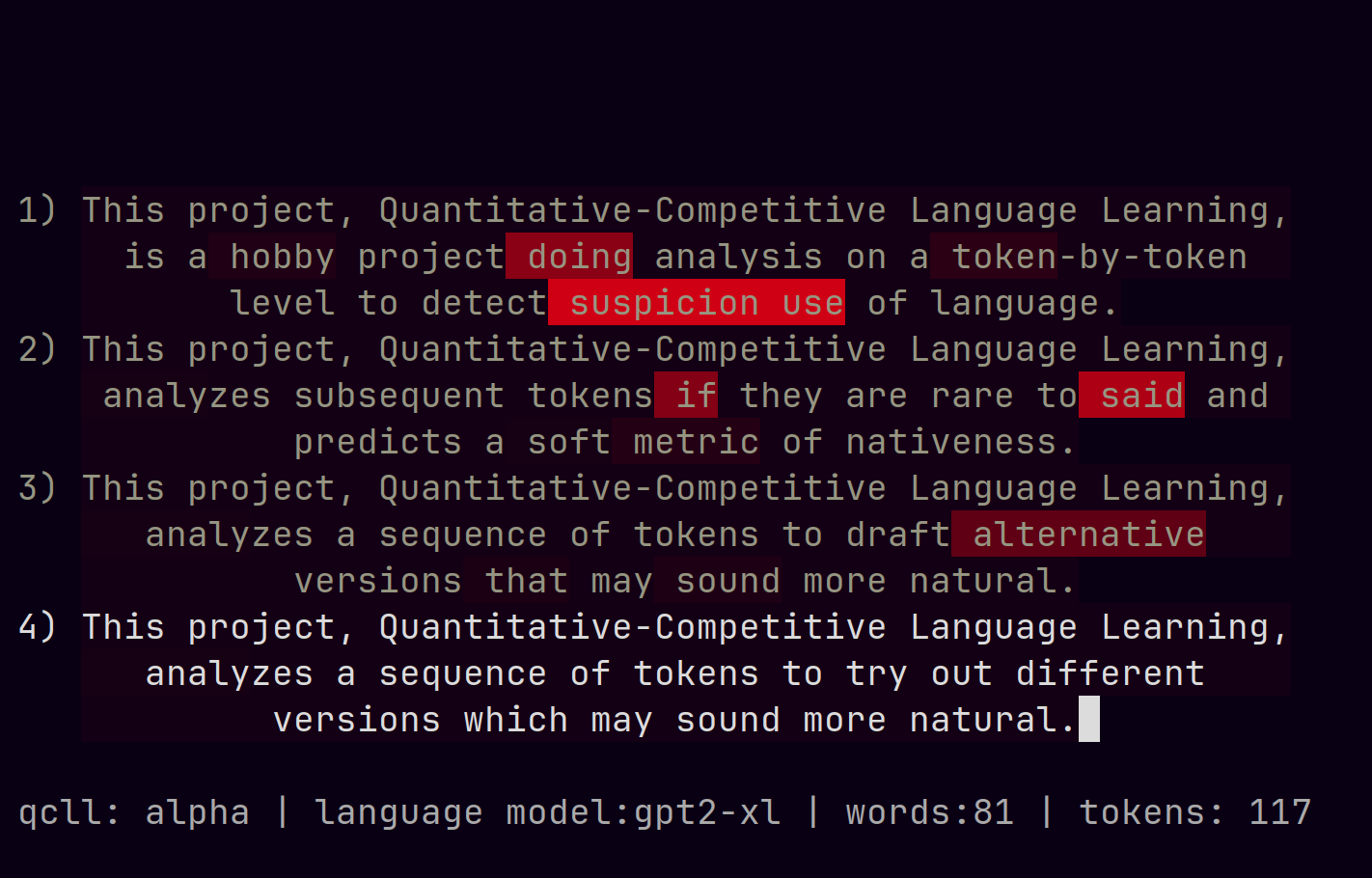
Quantitative-Competitive Language Learning
Sean Brynjólfsson
This is a toy project aiming to use a LLM as a model-of-language. That might seem redundant, but what I mean by that is I care about the actual distribution over tokens, not the sampling/generative procedure that LLMs are typically synonymous with. Given a distribution of tokens, I compute an approximate branching factor using the perplexity of the distribution and compare it with the user-supplied token probability; this gives a soft estimate for whether or not the model regards the next token as one of the possible continuations of the context preceding it. For example, if the branching factor is 40 but the token’s probability is much less than 1/40 there’s probably something weird going on.
What’s so competitive about this? Well, my vision is to be able to place users on a distribution that spans from noise, then to language-learners, then natives, then to the model itself. The key is to derive a stable metric which corresponds to “yeah, this sentence is plausibly written by a native”; something I think is possible if enough care is taken to normalize over the relative probability of equally-viable but not equally-likely tokens. With that, users could get empirical feedback and track their progress as they learn a foreign language and even compete with each other to produce the most or “highest quality” text.

Compositional Gaussian Splatting for Construction Sites
Sean Brynjólfsson*, Dyllan Hofflich*, Evan Zhang*, Daniel Qureshi*, Natalie Leung*
We investigate the potential applications of gaussian splatting on construction sites to capture a holsitic digital twin throughout the construction process via legged robots. This project was our collective introduction to gaussian splatting, so a large portion of it is dedicated to a review of currently existing methods. This was a great experience even though we did not acheive our goals.
We used NVIDIA Omniverse to model our simulated environment and an ANYmal-D equipped with a RGBD camera. One part of our team worked with the Blender-to-Omniverse connector to try and get realistic construction environs for us to simulate.


Visual Navigation with Traversability Priors
Sean Brynjólfsson*, William Pinstrup Huey*
Continuing our work with open-vocabulary traversability, we were interested in training smaller models on specific traversability scenarios. Our original model was too large to fit on the ANYmal’s NVIDIA Jetson processor and its inference speed was quite slow (~7s). Since we did not experiment with prompts that changed during rollout, we were wasting a lot of compute by preserving its open-vocabulary capabilities. Thus we chose to train a smaller model on the bigger model with a fixed prompt. For example, “you are a robot who cannot climb stairs”. Model distillation is not so interesting on its own, but being able to do so over an abstract description of traversability is quite useful.
In this paper, we demonstrate that weak traversability priors can be obtained from large open vocabulary image segmentation models and that they appear to be consistent across environments. We then apply model distillation techniques to train a smaller traversability prediction network capable of real time inference, and demonstrate a heuristic that uses this distilled network to perform obstacle avoidance when roaming freely.
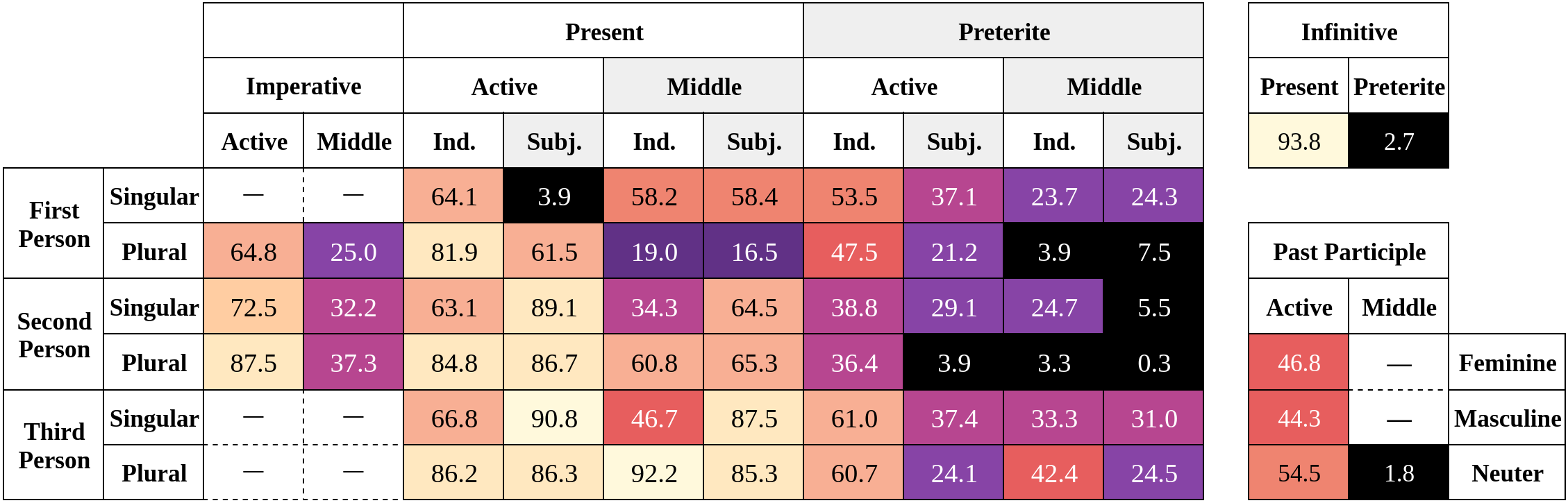
LLMímir: So, GPT-4, how well do you speak Old Norse?
Sean Brynjólfsson
Most people aren’t aware that Icelandic is GPT-4’s second language; but it is. What could this mean for its related, low-resource ancestor Old Norse?
Old Norse (often called Old Icelandic) is a language which is incredibly similar to modern Icelandic. For that reason, I was interested in investigating how trustworthy it might be for questions on Old Norse grammar and potentially for creative and academic/self-study uses. Would GPT-4 benefit from more exposure to Icelandic or would that bleed into its understanding of Old Norse?
This paper examines GPT-4 on all Old Norse verbs and their verb forms. The experiment was conducted at a temperature of 0 (since I could not afford to sample multiple responses per form) and with a blank context. This scenario should be nearly deterministic and yield low variance responses.



Let it SIMmer / Open-Vocabulary Traversability
Sean Brynjólfsson*, William Pinstrup Huey*
Generalizing to new and dynamic environments is a significant challenge in mobile robotics. Nowadays, vision-aware models are more prevalent and significantly powerful. These models are capable of producing robust, semantic features that make downstream tasks like navigation significantly easier. Images are rich enough to characterize many cues that geometric information alone does not provide.
Three implementations comprise our overall method. In total, our system allows for streaming from a robot to a compute node which then answers classification requests from users in either Isaac Sim or Rviz.
- Voxvis: An extension for NVIDIA Omniverse’s Isaac Sim to interface with the voxel segmentations; we also provide a similar accompanying Rviz visualization. Communication between the modules is implemented in ROS, making it suitable for both live, simulated, and replay data.
- OVT: An open-vocabulary traversability segmentation framework. This is a ros node that processes incoming RGB-D images and extracts embeddings for each pixel and then bundles it with odometry and pose data from the robot. (We don’t collapse the embeddings into a classification yet, we let it SIMmer)
- Voxseg: A bridge between OVT and Voxvis, Voxseg simultaneously updates the internal voxelized embeddings and handles requests from Voxvis for a particular user-specified, open-vocabulary classification over them.
We also implemented other helpful tools to generate environments in Omniverse, such as construction sites and forested scenes, (Isaac Stage GitHub). NOTE: This has not been updated to the latest major version of Isaac Sim/Orbit.


Fractal Raytracer
Sean Brynjólfsson*, Jack Otto*
This fractal raytracer was a creative assignment for Cornell’s CS4620 graphics course. The premise was simply to take the raytracer we had just completed in a prior assignment and augment it with some new feature. We chose to try generating some constructive solid geometry fractals. The idea is quite simple; our scene is composed of two types of objects: spheres and reentrant spheres. Rays which hit spheres bounce as they would ordinarily for solid geometry, rays which hit a reentrant sphere descend recursively into copies of the scene. We also treat the reentrant spheres as subtractive of the solid spheres they intersect, so rays that leave a subscene won’t end up inside solid geometry. If a ray passes through the subscene and doesn’t hit either a solid or reentrant primitive, it decrements its recursive depth until it has popped off all the layers it has descended.